Claude Fable 5 vs Opus 4.8, c'est le comparatif que j'ai pu sentir en plein milieu d'une journée de travail, au lieu de juste le lire d'abord. Hier après-midi, j'étais en pleine session Claude Code, au milieu d'un lot de publications pour ce site, quand j'ai basculé le modèle d'Opus 4.8 vers Fable 5 et j'ai juste continué. Même conversation, même tâche à moitié finie, seul le moteur en dessous a changé. Ce site tourne entièrement sur Claude, donc quand Anthropic a sorti Fable 5 le 9 juin j'ai senti le changement en plein travail de production. Voici ce que je peux vous dire après un jour, ce que disent les chiffres publiés, et ce que je ne peux honnêtement pas encore vous dire.
The short answer
Fable 5 est le premier modèle du nouveau palier Mythos-class d'Anthropic, un cran au-dessus d'Opus. Il coûte exactement 2x ($10 / $50 par million de tokens contre $5 / $25), avec le même context window de 1M et la même sortie max de 128K. L'écart est le plus net sur le travail dur et de longue haleine, et bien plus faible sur les tâches courtes et cadrées. Une réserve : les requêtes cybersécurité, bio/chimie et distillation sont reroutées vers Opus 4.8, donc sur ces sujets vous payez le prix Fable pour des réponses Opus. Mon avis après un jour : garder Opus 4.8 comme cheval de trait par défaut, envoyer les longs jobs autonomes et difficiles à Fable 5.

{kind=link}
Hier après-midi, j'étais en pleine session Claude Code, au milieu d'un lot de publications pour ce site, quand j'ai basculé le modèle d'Opus 4.8 vers Fable 5. Et j'ai juste continué. Même conversation. Même tâche à moitié finie. La seule chose qui a changé, c'est le moteur en dessous.
Un peu de contexte, pour que vous sachiez d'où je parle. Ce site tourne entièrement sur Claude. Les outils, le pipeline d'articles, les 150+ pages qu'on a traduites, les scripts de publication via l'API REST : tout ça se construit et se maintient dans des sessions Claude Code qui font du vrai travail de production, pas des prompts jouets. Alors quand Anthropic a sorti Fable 5 le 9 juin, je n'ai pas eu le temps de lire les annonces. J'ai senti le changement en plein milieu d'une journée de boulot.
Un jour plus tard, voici ce que je peux vous dire, ce que disent les chiffres publiés, et ce que, honnêtement, je ne peux pas encore vous dire.
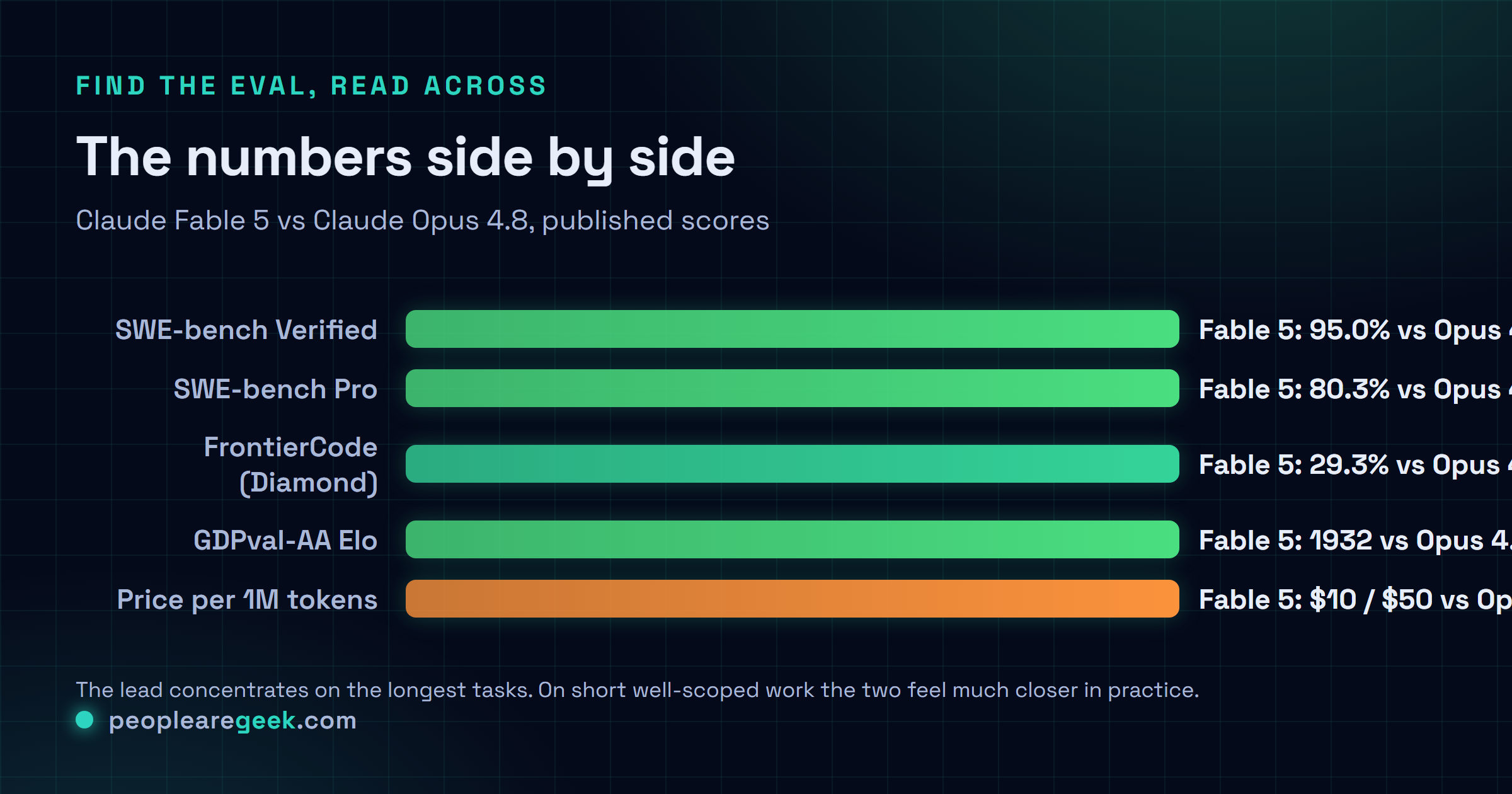
Les chiffres côte à côte
| Claude Fable 5 | Claude Opus 4.8 | |
|---|---|---|
| Palier | Mythos-class (nouveau, au-dessus d'Opus) | Vaisseau amiral du palier Opus |
| ID modèle API | claude-fable-5 | claude-opus-4-8 |
| Prix par 1M de tokens | $10 en entrée / $50 en sortie | $5 en entrée / $25 en sortie |
| Context window | 1M tokens | 1M tokens |
| Sortie max | 128K | 128K |
| SWE-bench Verified | 95.0% | 88.6% |
| SWE-bench Pro | 80.3% | 69.2% |
| FrontierCode (Diamond) | 29.3% | 13.4% |
| Elo GDPval-AA | 1932 | 1890 |
| Disponibilité | API Anthropic, applis claude.ai, GitHub Copilot (GA), Amazon Bedrock | API Anthropic, applis claude.ai, GitHub Copilot (GA), Amazon Bedrock |
C'est quoi, au juste, le palier Mythos ?
Pendant des années, la gamme Claude se lisait Haiku, Sonnet, Opus. Petit, moyen, gros. Point. Fable 5 casse cette échelle : c'est le premier modèle public d'un nouveau palier Mythos-class qui se place carrément au-dessus d'Opus. Opus 4.8 n'est ni remplacé ni retiré. Il reste le vaisseau amiral du palier Opus, et Anthropic le facture en conséquence.
Bon à savoir : Fable 5 est lui-même le visage abordable de ce palier. Il coûte moins de la moitié de ce que coûtait Mythos Preview, et c'est sans doute tout l'intérêt. Vous prenez la capacité de classe frontière, vous limez les arêtes les plus dangereuses (j'y reviens plus bas), et d'un coup vous pouvez le livrer à tout le monde. Il existe aussi un frère jumeau, Mythos 5, que seuls les partenaires peuvent toucher, et il compte pour une raison bien précise que j'aborde dans la section sécurité.
La disponibilité est inhabituellement large pour un modèle frontière au jour 1. L'API Anthropic, les applis claude.ai, GitHub Copilot en GA, et Amazon Bedrock, le tout dès le 9 juin. Pas de théâtre de liste d'attente.
La surface API est la même qu'Opus 4.8 : adaptive thinking uniquement, pas de réglages temperature, top_p ou top_k, un paramètre effort de low à max. Un breaking change va piquer ceux qui copient-collent leurs configs : envoyer explicitement un thinking de type disabled renvoie une erreur 400 sur Fable 5. Omettez le paramètre, tout simplement. Il m'a fallu une requête ratée pour l'apprendre, de rien.
Les benchmarks de code, lus honnêtement
Le chiffre en une, c'est 95.0% sur SWE-bench Verified, contre 88.6% pour Opus 4.8. Dit comme ça, ça paraît modeste. Lisez-le dans l'autre sens : Fable réduit le taux d'échec de plus de moitié. Tout en haut d'un benchmark saturé, c'est cette lecture-là qui compte.
SWE-bench Pro est plus rude et l'écart s'y creuse : 80.3% vs 69.2%. Et pour ceux qui suivent le classement, GPT-5.5 est à 58.6% et Gemini 3.1 Pro à 54.2% sur la même éval, donc ce n'est pas juste une course interne en famille. Les modèles Claude tiennent les deux premières places.

{kind=link}
Le chiffre qui m'a vraiment fait lever la tête, c'est FrontierCode, l'éval de Cognition, sur le split Diamond : 29.3% vs 13.4%. Plus du double d'Opus, et GPT-5.5 y fait 5.7%. FrontierCode est bâti sur le genre de tâches d'ingénierie longues et tordues où les modèles s'écroulent traditionnellement en cours de route. Doubler sur cette éval, ce n'est pas le même genre d'affirmation que deux points de plus sur un leaderboard saturé.
Hors code pur, le motif se répète avec moins d'amplitude. Elo GDPval-AA : 1932 vs 1890. L'éval vision GDP.pdf : 29.8% vs 22.5%. Sur le Hebbia Finance Benchmark, Fable 5 a signé le meilleur score tous modèles confondus. Et les résultats longue durée sont franchement la partie la plus étrange de la model card : avec mémoire persistante, sur l'éval Slay the Spire, l'amélioration de Fable 5 est d'environ 3x par rapport à Opus 4.8. Une tâche de recherche en physique qui a pris quatre jours à GPT-5.5, Fable 5 l'a bouclée en 36 heures.
Maintenant, la partie honnête. Les analystes qui ont creusé les détails retombent tous sur la même nuance : l'avance de Fable est maximale sur le travail long et non supervisé, et sur les tâches courtes bien cadrées, les deux modèles sont nettement plus proches. Ma première journée colle à ça, pour ce qu'une journée vaut. N'attendez pas que vos petits refactors rapides soient transfigurés.
Verdict benchmarks. Un écart réel, mais inégalement réparti. Sur le travail long et autonome, Fable 5 fait quelque chose de réellement nouveau (FrontierCode plus que doublé, 3x sur la mémoire longue durée). Sur le quotidien, Opus 4.8 était déjà excellent et le reste. Je note juste que les benchmarks récompensent pile le type de travail qu'on a le plus de mal à déléguer aujourd'hui.
Le calcul du prix : quand est-ce que le 2x se justifie ?
$10 en entrée, $50 en sortie, contre $5 et $25. Un doublement net, sans astérisque. Même context window de 1M des deux côtés, même sortie max de 128K, donc vous n'achetez pas plus d'espace. Vous achetez plus de capacité par token.
Voici par contre la subtilité que le prix affiché cache. Fable finit souvent en moins de tours et moins de tokens. Un job qu'Opus tourne trois fois, Fable le réussit parfois du premier coup. Quand ça arrive, l'écart de coût effectif descend bien en dessous de 2x. Quand ça n'arrive pas, vous avez payé double pour la même réponse. J'ai vu les deux cette semaine, et je n'ai pas encore assez de sessions pour vous donner le ratio.
Donc le calcul ressemble à ça. Tâche courte et cadrée, résultat à peu près égal : le 2x est du pur surcoût, restez sur Opus. Tâche longue et dure où Opus aurait besoin de baby-sitting et de reprises : le 2x peut se rembourser en moins d'itérations et moins de votre propre temps passé à surveiller. Votre temps à vous, c'est le token hors de prix que personne ne facture.
Si vous voulez de vrais chiffres pour votre charge de travail plutôt que mes approximations, notre calculateur de coût IA et notre compteur de tokens feront l'arithmétique avec vos vraies tailles de prompt.
La réserve du routage sécurité (les gens de la cyber, lisez ça)
Ce point compte tout particulièrement pour le lectorat de ce site, donc je ne vais pas l'enterrer. Fable 5 embarque un routage de sécurité : les requêtes qui touchent à la cybersécurité, à la biologie et la chimie, ou à la distillation de modèles retombent sur Opus 4.8. Anthropic dit que ça concerne moins de 5% des sessions, et pour la plupart des utilisateurs c'est vrai. Pour les lecteurs d'un site rempli d'outils réseau et sécu, votre taux sera plus élevé que 5%, je suis prêt à le parier.
Conséquence pratique : posez à Fable 5 une question d'analyse d'exploit ou de durcissement et vous obtenez littéralement le cerveau d'Opus 4.8 au prix de Fable 5. Pas un Fable dégradé. L'autre modèle, le vrai, facturé au nouveau tarif. Pour les charges très orientées cyber, le choix rationnel est brutal : appelez directement claude-opus-4-8 et gardez la différence.
Le contexte derrière ce routage : Mythos 5, le jumeau réservé aux partenaires, a marqué 78% sur ExploitBench contre 40% pour Opus 4.8. Cette capacité existe. Elle est délibérément absente du modèle public. Que vous y voyiez de la responsabilité ou un teaser pour une offre entreprise, c'est une affaire de tempérament. Moi je penche pour responsable, de justesse, mais reposez-moi la question après le premier writeup de jailbreak.
Premières impressions en conditions réelles (subjectif, jour 1)
Tout ce qui suit, c'est la première journée d'une seule personne. Pas de mesures, pas d'échantillon, prenez-le avec des pincettes.
Le basculement en pleine session a été un non-événement, ce qui est en soi un compliment. Mêmes outils, mêmes fichiers, il a repris là où Opus s'était arrêté. Ce que j'ai remarqué en premier, c'est le rythme : Fable semble planifier davantage avant de toucher à quoi que ce soit, puis avance par étapes plus grandes, plus assumées. Opus 4.8 a tendance à grignoter. Éditer, vérifier, rééditer. Fable lit plus, puis fait le truc une fois.
Sur un script de publication multi-fichiers où je m'attendais normalement à deux ou trois allers-retours de correction, il a sorti la bonne structure du premier coup. Une fois. C'est une anecdote, pas un benchmark, et je me suis déjà fait avoir par les effets de halo du jour 1, quand le nouveau modèle paraît plus malin juste parce que je le regarde de plus près.
Sur la prose, et c'est l'avis dont je suis le moins sûr, j'ai l'impression qu'il tient un long jeu de consignes plus fidèlement en fin de session. Nos règles d'écriture ici sont pointilleuses (vous êtes en train de lire leur résultat) et la dérive sur une longue session, c'est normalement là que les modèles glissent. Une journée, c'est très loin de suffire pour affirmer que c'est réel. C'est peut-être juste moi qui ai envie d'y croire.
Rien ne m'a paru pire pour l'instant. Le résumé honnête, c'est : sur le travail de routine, je ne suis pas sûr que je saurais les distinguer à l'aveugle. Sur les jobs plus retors, quelque chose semble effectivement différent, et les benchmarks suggèrent que cette impression n'est pas un pur placebo.
Qui devrait basculer, qui devrait s'abstenir
Ma recommandation après un jour, et après lecture des fiches techniques : routez par tâche. Ne changez pas un défaut global en appelant ça une stratégie.
Restez sur Opus 4.8 pour : le code de tous les jours, les tâches courtes et cadrées, le travail de contenu, tout ce qui est interactif où vous pilotez de près, et absolument tout ce qui touche à la cybersécurité (vous seriez de toute façon rerouté vers Opus, au double du prix). Ça reste un modèle superbe. Rien dans le 9 juin ne l'a rendu moins bon.
Envoyez à Fable 5 : les longs jobs autonomes que vous voulez lancer puis laisser tourner. Les gros refactors multi-fichiers, les runs d'agent d'une heure ou plus, les migrations, les tâches façon recherche où les chiffres longue durée (3x avec mémoire persistante, 36 heures contre 4 jours) mesurent exactement la bonne dimension. Sur celles-là, le 2x a une vraie chance de se rembourser.
En résumé. Opus 4.8 reste mon cheval de trait par défaut. Fable 5 est le spécialiste que je sors désormais quand le job est long et sans supervision. Si votre travail relève surtout du premier cas, vous pouvez ignorer cette mise à jour et n'y perdre presque rien. S'il relève du second, c'est le plus gros saut sur un seul modèle que j'aie vu depuis le passage d'Opus en 4.x, et oui, je sais à quel point ça sonne jour 1.
Sources
- Tom's Hardware: Claude Fable 5 brings Mythos to the masses
- TechCrunch: Anthropic releases Claude Fable 5
- Vellum: Claude Fable 5 and Mythos 5 benchmarks explained
- GitHub changelog: Claude Fable 5 GA for Copilot
Questions fréquentes
Claude Fable 5 remplace-t-il Opus 4.8 ?
Non. Fable 5 inaugure un nouveau palier Mythos-class au-dessus d'Opus, et Opus 4.8 reste le vaisseau amiral du palier Opus à son tarif actuel de $5 / $25. Voyez ça comme une nouvelle étagère vissée au-dessus de l'ancienne. Les deux restent pleinement disponibles côte à côte sur l'API, les applis, GitHub Copilot et Bedrock.
Fable 5 coûte combien de plus ?
Exactement le double : $10 par million de tokens en entrée et $50 par million en sortie, contre $5 / $25 pour Opus 4.8. L'écart effectif peut être plus petit parce que Fable finit souvent les jobs en moins de tours et moins de tokens au total, mais budgétez sur le 2x et traitez toute économie comme un bonus.
Fable 5 a-t-il un context window plus grand ?
Non, et ça surprend du monde. Les deux modèles acceptent 1M de tokens de contexte et produisent jusqu'à 128K en sortie. Ce que le surcoût achète, c'est de la capacité, les plafonds restant identiques. Si votre goulot d'étranglement, c'est de faire tenir une énorme codebase dans le contexte, Fable 5 ne bouge pas ce plafond d'un pouce.
Fable 5 est-il vraiment meilleur en code ?
Sur les évals publiées, clairement : 95.0% vs 88.6% sur SWE-bench Verified, 80.3% vs 69.2% sur SWE-bench Pro, et 29.3% vs 13.4% sur le split Diamond de FrontierCode, soit plus du double. L'avance se concentre sur les tâches les plus longues. Sur les correctifs rapides et bien cadrés, les deux paraissent beaucoup plus proches en pratique.
Pourquoi mes questions sécurité à Fable 5 ressemblent-elles à du Opus ?
Parce que c'en est, littéralement. Fable 5 reroute les requêtes cybersécurité, biologie/chimie et distillation de modèles vers Opus 4.8, un repli qui selon Anthropic touche moins de 5% des sessions au global. Si votre travail est surtout de la sécurité, appelez claude-opus-4-8 directement et payez moitié prix pour des réponses identiques.
Dois-je changer mon code API pour utiliser Fable 5 ?
À peine. La surface est la même qu'Opus 4.8 : adaptive thinking uniquement, pas de temperature, top_p ni top_k, et un paramètre effort de low à max. Un seul breaking change : passer explicitement un thinking de type disabled renvoie maintenant un 400 sur Fable 5. Omettez le paramètre et tout va bien.