Claude Fable 5 vs Opus 4.8 is the comparison I got to feel in the middle of a workday, not read about first. Yesterday afternoon I was mid-session in Claude Code, halfway through a batch of publishing work, when I swapped the model from Opus 4.8 to Fable 5 and just kept going. Same conversation, same half-finished task, only the engine underneath changed. This entire site runs on Claude, so when Anthropic shipped Fable 5 on June 9 I got to feel the swap during real production work. Here is what I can tell you after one day, what the published numbers say, and what I honestly cannot tell you yet.
The short answer
Fable 5 is the first model of Anthropic's new Mythos-class tier, a step above Opus. It costs exactly 2x ($10 / $50 per million tokens vs $5 / $25), with the same 1M context and 128K max output. The gap is biggest on hard, long-horizon work and much smaller on short scoped tasks. One caveat: cybersecurity, bio/chem and distillation requests get routed back to Opus 4.8, so on those topics you pay Fable prices for Opus answers. My call after a day: keep Opus 4.8 as the default workhorse, send the long autonomous hard jobs to Fable 5.

{kind=link}
Yesterday afternoon I was mid-session in Claude Code, halfway through a batch of publishing work for this site, when I swapped the model from Opus 4.8 to Fable 5 and just kept going. Same conversation. Same half-finished task. The only thing that changed was the engine underneath.
Some context so you know where I'm standing. This entire site runs on Claude. The tools, the article pipeline, the 150+ pages we translated, the REST API publishing scripts: all of it gets built and maintained in Claude Code sessions doing real production work, not toy prompts. So when Anthropic shipped Fable 5 on June 9, I didn't get to read about it first. I got to feel the swap in the middle of a workday.
One day in, here's what I can tell you, what the published numbers say, and what I honestly can't tell you yet.
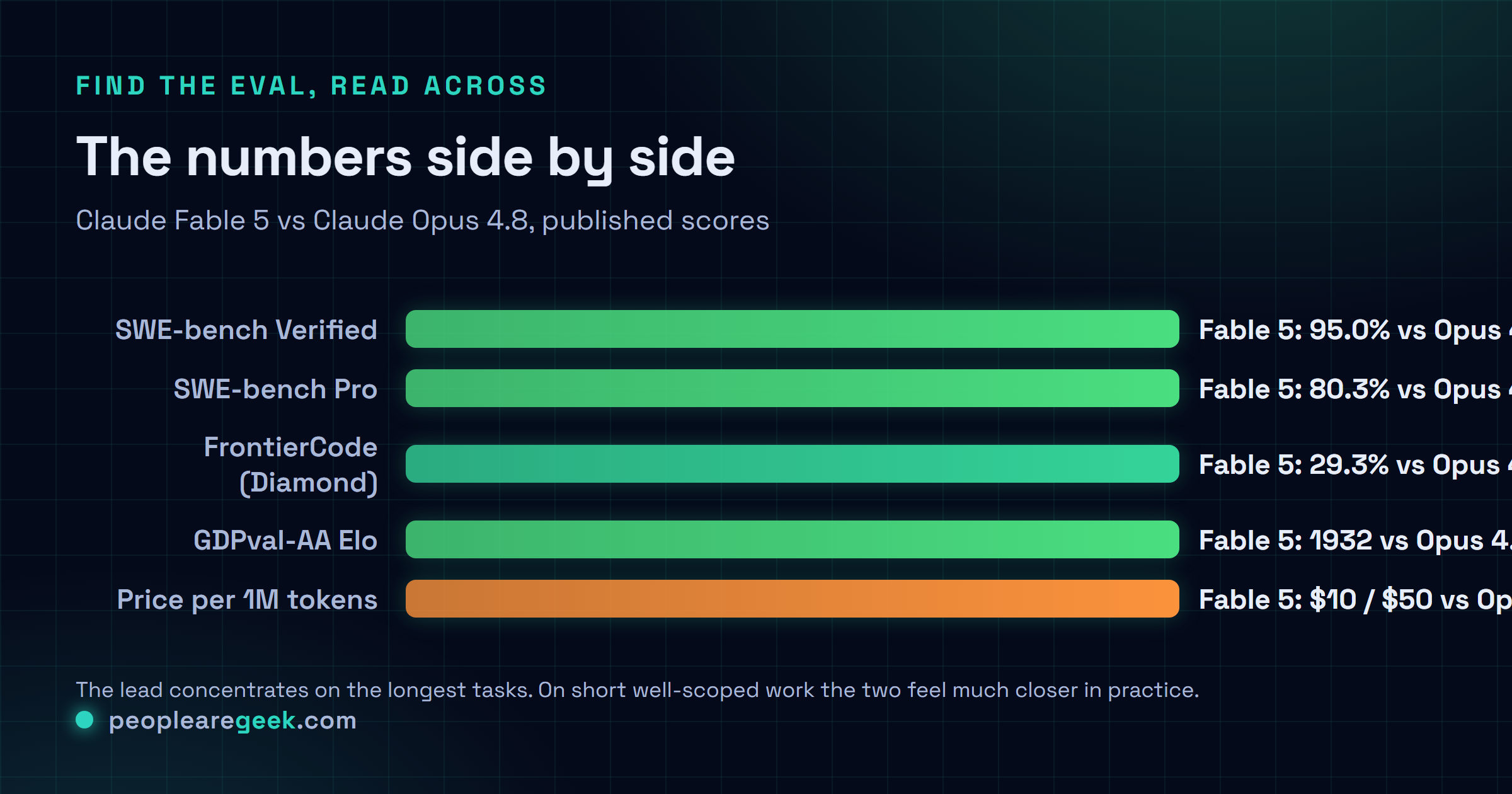
The numbers side by side
| Claude Fable 5 | Claude Opus 4.8 | |
|---|---|---|
| Tier | Mythos-class (new, above Opus) | Opus-tier flagship |
| API model ID | claude-fable-5 | claude-opus-4-8 |
| Price per 1M tokens | $10 input / $50 output | $5 input / $25 output |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K | 128K |
| SWE-bench Verified | 95.0% | 88.6% |
| SWE-bench Pro | 80.3% | 69.2% |
| FrontierCode (Diamond) | 29.3% | 13.4% |
| GDPval-AA Elo | 1932 | 1890 |
| Availability | Anthropic API, claude.ai apps, GitHub Copilot (GA), Amazon Bedrock | Anthropic API, claude.ai apps, GitHub Copilot (GA), Amazon Bedrock |
What the Mythos tier actually is
For years the Claude lineup read Haiku, Sonnet, Opus. Small, medium, big. Done. Fable 5 breaks that ladder: it's the first public model in a new Mythos-class tier that sits above Opus entirely. Opus 4.8 isn't being replaced or retired. It stays the Opus-tier flagship, and Anthropic prices it accordingly.
Worth knowing: Fable 5 is itself the cheaper face of this tier. It costs less than half of what Mythos Preview did, which is presumably the point. You take the frontier-class capability, sand off the most dangerous edges (more on that below), and you can suddenly ship it to everyone. There's also a sibling called Mythos 5 that only partners can touch, and it matters for one specific reason I'll get to in the security section.
Availability is unusually broad for a day-one frontier model. The Anthropic API, the claude.ai apps, GitHub Copilot in GA, and Amazon Bedrock, all from June 9. No waitlist theater.
The API surface is the same as Opus 4.8: adaptive thinking only, no temperature or top_p or top_k knobs, an effort setting from low to max. One breaking change will bite people who copy-paste configs: explicitly sending a thinking type of disabled returns a 400 error on Fable 5. Omit the parameter instead. Took me one failed request to learn that, you're welcome.
The coding benchmarks, read honestly
The headline number is 95.0% on SWE-bench Verified, against 88.6% for Opus 4.8. That sounds modest. Read it the other way: Fable cuts the failure rate by more than half. Up at the top of a saturated benchmark, that's the comparison that matters.
SWE-bench Pro is harsher and the gap is wider: 80.3% vs 69.2%. And for the scoreboard watchers, GPT-5.5 sits at 58.6% and Gemini 3.1 Pro at 54.2% on that same eval, so this isn't just an internal family race. The Claude models hold the top two slots.

{kind=link}
The number that actually made me sit up is FrontierCode, Cognition's eval, on the Diamond split: 29.3% vs 13.4%. More than double Opus, and GPT-5.5 scores 5.7% there. FrontierCode is built from the kind of long, gnarly engineering tasks where models traditionally fall apart partway through. A doubling on that eval is not the same kind of claim as two more points on a saturated leaderboard.
Outside pure code, the pattern repeats at lower amplitude. GDPval-AA Elo: 1932 vs 1890. The GDP.pdf vision eval: 29.8% vs 22.5%. On the Hebbia Finance Benchmark, Fable 5 posted the highest score of any model. And the long-horizon results are frankly the weirdest part of the model card: with persistent memory, on the Slay the Spire eval, Fable 5's improvement is roughly 3x over Opus 4.8. A physics research task that took GPT-5.5 four days, Fable 5 finished in 36 hours.
Now the honest part. Analysts who've dug into the breakdowns keep landing on the same nuance: Fable's lead is biggest on the long unsupervised stuff, and on short well-scoped tasks the two models are much closer. My first day matches that, for whatever a day is worth. Don't expect your quick refactors to feel transformed.
Benchmark verdict. Real gap, unevenly distributed. On the long autonomous work, Fable 5 is doing something genuinely new (FrontierCode more than doubled, 3x on long-horizon memory). On the everyday stuff, Opus 4.8 was already excellent and still is. I'll just note that the benchmarks happen to reward exactly the work that's hardest to delegate today.
The price math: when is 2x worth it?
$10 in, $50 out, against $5 and $25. A clean doubling, no asterisks. Same 1M context window on both, same 128K max output, so you're not buying more room. You're buying more capability per token.
Here's the wrinkle that the sticker price hides, though. Fable often finishes in fewer turns and fewer tokens. A job Opus circles three times, Fable sometimes nails on the first pass. When that happens, the effective cost gap shrinks well below 2x. When it doesn't happen, you paid double for the same answer. I've seen both this week, and I don't have enough sessions yet to tell you the ratio.
So the math goes like this. Short scoped task, outcome roughly equal: the 2x is pure overhead, stay on Opus. Long hard task where Opus would need babysitting and retries: the 2x can pay for itself in fewer iterations and less of your own time watching it. Your own time is the expensive token nobody prices in.
If you want real numbers for your workload instead of my hand-waving, our AI cost calculator and token counter will do the arithmetic with your actual prompt sizes.
The safety routing caveat (cyber people, read this)
This one matters for this site's audience specifically, so I'm not burying it. Fable 5 ships with safety routing: requests touching cybersecurity, biology and chemistry, or model distillation fall back to Opus 4.8. Anthropic says it affects under 5% of sessions, and for most users that's true. For readers of a site full of network and security tooling, your hit rate will be higher than 5%, I'd bet on it.
Practical consequence: ask Fable 5 about exploit analysis or hardening work and you're literally getting Opus 4.8's brain at Fable 5's price. Not a degraded Fable. The actual other model, billed at the new rate. For cyber-heavy workloads, the rational move is blunt: just call claude-opus-4-8 directly and keep the savings.
The context behind the routing: Mythos 5, the partner-only sibling, scored 78% on ExploitBench against Opus 4.8's 40%. That capability exists. It is deliberately not in the public model. Whether you read that as responsible or as a teaser for an enterprise tier is a matter of temperament. I land on responsible, narrowly, but ask me again after the first jailbreak writeup.
Early hands-on impressions (subjective, day one)
Everything in this section is one person's first day. No measurements, no sample size, hold it loosely.
The mid-session switch itself was a non-event, which is its own kind of praise. Same tools, same files, picked up where Opus left off. What I noticed first was pacing: Fable seems to plan more before touching anything, then moves in bigger, more committed steps. Opus 4.8 has a tendency to nibble. Edit, check, edit again. Fable reads more, then does the thing once.
On a multi-file publishing script I'd normally expect a couple of correction rounds on, it got the structure right the first time. Once. That's an anecdote, not a benchmark, and I've been burned before by day-one halo effects where the new model feels smarter because I'm paying closer attention.
On prose, and this is the take I'm least sure of, I think I notice it holding a long instruction set more faithfully deep into a session. Our writing rules here are picky (you're reading the output of them right now) and drift over a long session is normally where models slip. One day is nowhere near enough to claim that's real. Maybe it's just me wanting it to be.
Nothing has felt worse so far. The honest summary is: on routine work I'm not sure I could pick the two apart blind. On the gnarlier jobs, something does feel different, and the benchmarks suggest that feeling isn't pure placebo.
Who should switch, who shouldn't
My recommendation after a day, and after the spec sheets: route by task. Don't flip a global default and call it a strategy.
Stay on Opus 4.8 for: everyday coding, short scoped tasks, content work, anything interactive where you're steering closely, and absolutely anything cybersecurity-related (you'd be routed to Opus anyway, at double the price). It remains a superb model. Nothing about June 9 made it worse.
Send to Fable 5: long autonomous jobs you want to fire and walk away from. Big multi-file refactors, hour-plus agent runs, migrations, the research-shaped tasks where the long-horizon numbers (3x with persistent memory, 36 hours vs 4 days) are exactly the dimension being measured. On those, the 2x has a real chance of paying for itself.
Bottom line. Opus 4.8 stays my default workhorse. Fable 5 is the specialist I now reach for when the job is long and unsupervised. If your work is mostly the first kind, you can skip this upgrade entirely and lose very little. If it's the second kind, the upgrade is the biggest single-model jump I've seen since Opus went 4.x, and yes, I know how day-one that sounds.
Sources
- Tom's Hardware: Claude Fable 5 brings Mythos to the masses
- TechCrunch: Anthropic releases Claude Fable 5
- Vellum: Claude Fable 5 and Mythos 5 benchmarks explained
- GitHub changelog: Claude Fable 5 GA for Copilot
Frequently asked questions
Is Claude Fable 5 a replacement for Opus 4.8?
No. Fable 5 opens a new Mythos-class tier above Opus, and Opus 4.8 stays the current Opus-tier flagship at its existing $5 / $25 pricing. Think of it as a new shelf bolted on above the old one. Both are fully available side by side on the API, the apps, GitHub Copilot and Bedrock.
How much more expensive is Fable 5?
Exactly double: $10 per million input tokens and $50 per million output, against $5 / $25 for Opus 4.8. The effective gap can be smaller because Fable often finishes jobs in fewer turns and fewer total tokens, but plan your budget on the 2x and treat any savings as a bonus.
Does Fable 5 have a bigger context window?
No, and that surprises people. Both models take 1M tokens of context and emit up to 128K of output. What the premium buys is capability, while the ceilings stay identical. If your bottleneck is fitting a giant codebase into context, Fable 5 doesn't move that ceiling at all.
Is Fable 5 actually better at coding?
On the published evals, clearly: 95.0% vs 88.6% on SWE-bench Verified, 80.3% vs 69.2% on SWE-bench Pro, and 29.3% vs 13.4% on FrontierCode's Diamond split, which is more than double. The lead concentrates on the longest tasks. On quick, well-scoped fixes the two feel much closer in practice.
Why do my security questions to Fable 5 feel the same as Opus?
Because they literally are. Fable 5 routes cybersecurity, biology/chemistry and model-distillation requests back to Opus 4.8, a fallback Anthropic says affects under 5% of sessions overall. If your work is mostly security, call claude-opus-4-8 directly and pay half for the identical answers.
Do I need to change my API code to use Fable 5?
Barely. The surface matches Opus 4.8: adaptive thinking only, no temperature, top_p or top_k, and an effort parameter from low to max. One breaking change: explicitly passing a thinking type of disabled now returns a 400 on Fable 5. Just omit the parameter and you're fine.