L'antisèche curl que tu dégaines vraiment met d'abord les recettes utiles : télécharger un fichier en gardant son nom avec curl -O, choisir le nom toi-même avec -o, suivre les redirections avec -L, jeter un oeil aux en-têtes seuls avec -I, et faire un POST JSON vers une API avec -d plus un en-tête content-type. Le truc pénible avec curl, ce n'est pas qu'il soit difficile, c'est qu'il a environ quatre cents options et que tu n'en utilises jamais que huit, jamais celles dont tu te souviens. Voilà donc le kit qui marche, regroupé par ce que tu cherches à faire. Tu copies, tu changes l'URL, et c'est parti.
The short answer
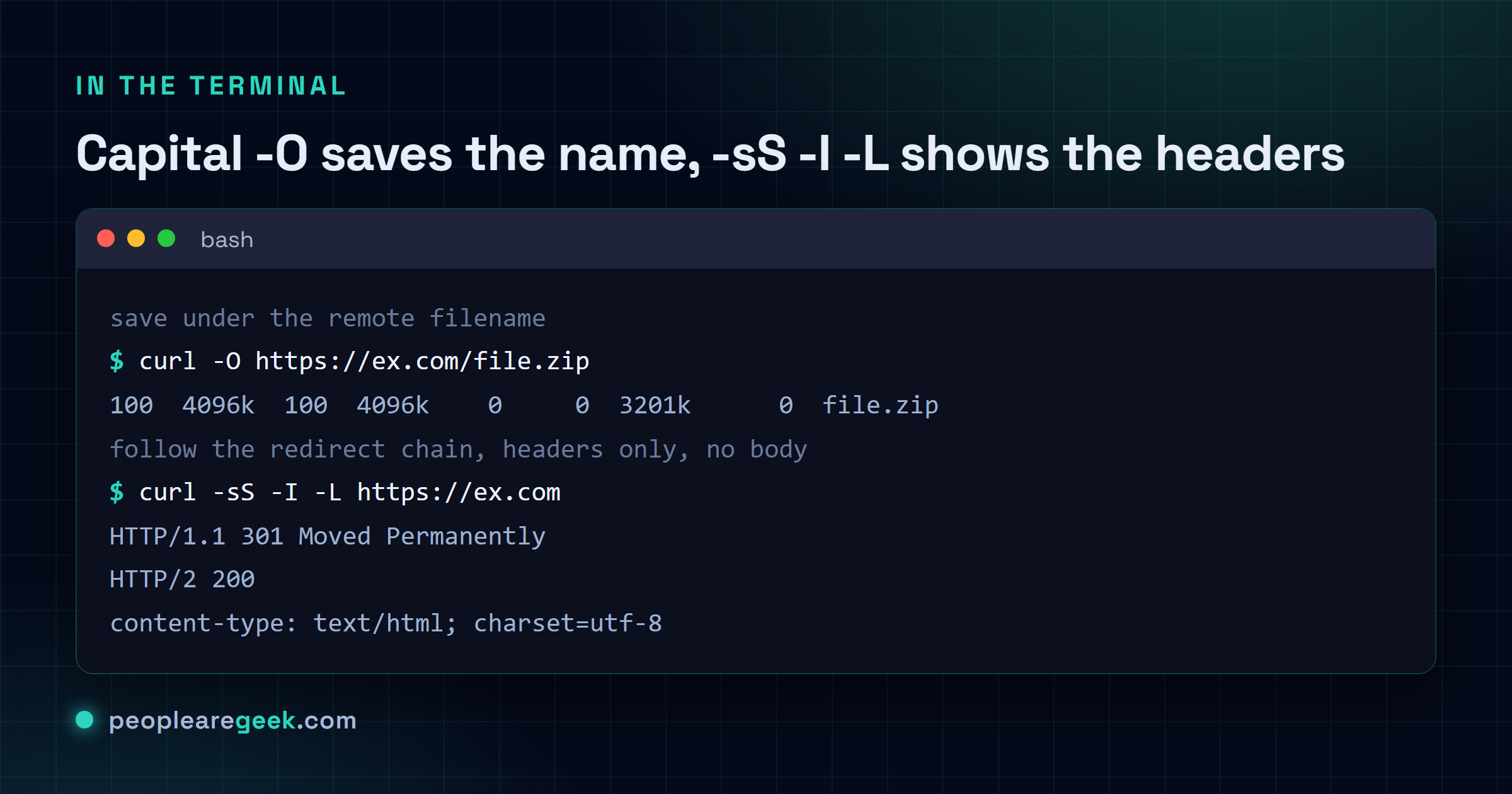
Télécharge en gardant le nom distant avec curl -O, choisis le nom toi-même avec
curl -o, suis les redirections avec curl -L, récupère les en-têtes seuls avec curl -I,
et fais un POST JSON avec curl -H "Content-Type: application/json" -d '{"id":7}'. Pour
tout ce qui est scripté, préfère -sS au -s tout seul pour que les erreurs remontent quand même.
Tu veux récupérer un fichier depuis une URL, ou tester une API et voir ce qu'elle te renvoie vraiment. C'est la raison pour laquelle on ouvre curl neuf fois sur dix, donc les recettes pour télécharger et suivre les redirections sont tout en haut. Tu copies, tu changes l'URL, et c'est parti. Le truc pénible avec curl, ce n'est pas qu'il soit difficile. C'est qu'il a environ quatre cents options et que tu n'en utilises jamais que huit, jamais celles dont tu te souviens.
Petit repérage avant, ca évite des cheveux blancs. curl parle HTTP (et tout un tas d'autres protocoles) et balance la réponse a l'écran par défaut. Il ne sauvegarde rien tant que tu ne le lui demandes pas, il ne suit aucune redirection sans qu'on l'y invite, et il t'affichera joyeusement un fichier binaire en plein terminal jusqu'a le rendre illisible. Du coup les deux premières options a connaitre, ce sont celles qui disent "enregistre ca" et "suis la piste".

{kind=link}
Télécharger un fichier (et garder son nom)
C'est celle que tout le monde veut en premier. Par défaut curl affiche la réponse sur la sortie standard, parfait pour une page web et catastrophique pour un zip. Deux options corrigent ça, et la différence entre les deux fait trébucher tout le monde. Le -O majuscule enregistre le fichier sous le nom qu'il avait sur le serveur. Le -o minuscule te laisse choisir le nom. Même lettre, casse différente, comportement totalement différent.
| Commande | Ce qu'elle fait |
|---|---|
curl -O https://ex.com/file.zip | Enregistre sous file.zip, le nom distant (O majuscule) |
curl -o out.zip https://ex.com/f | Enregistre sous un nom que tu choisis, ici out.zip (o minuscule) |
curl -L -O https://ex.com/file.zip | Télécharge en suivant les redirections, ce que font la plupart des liens |
curl -C - -O https://ex.com/big.iso | Reprend un téléchargement à moitié fini là où il s'est arrêté |
Franchement : associe -O avec -L presque à chaque fois. Énormément d'URL de téléchargement sont en réalité une redirection vers un CDN ou un miroir, et le -O tout seul enregistrera tranquillement la minuscule page de redirection sous file.zip, qui ensuite ne s'ouvrira pas, et tu vas passer dix minutes à chercher pourquoi. Demande-moi comment je le sais.
Reprendre un téléchargement coupé en plein vol
Gros fichier, connexion capricieuse, ça lâche à 80 pour cent. Pas besoin de tout recommencer. curl -C - -O reprend le téléchargement là où il s'était arrêté, et ce - nu après -C dit à curl de calculer tout seul le point de reprise plutôt que de compter les octets à sa place. Le hic, c'est que le serveur doit gérer les requêtes de plage pour que ça marche, et la plupart des serveurs de fichiers le font, mais l'un ou l'autre ne le fera pas et tu récupéreras tout depuis le début.
Suivre les redirections avec -L
Voilà le piège qui fait perdre le plus de temps avec curl. Par défaut il ne suit pas les redirections. Tu vises une URL, le serveur répond "301, c'est ailleurs maintenant", curl affiche ça et s'arrête, et tu restes devant une réponse qui a l'air vide à te demander ce qui a cassé. Rien n'a cassé. Il te manque juste -L.
| Commande | Ce qu'elle fait |
|---|---|
curl https://ex.com | Récupère une fois et s'arrête à la redirection, te montrant le 301, pas la cible |
curl -L https://ex.com | Suit la chaîne de redirections jusqu'à la vraie destination |
curl -L -o page.html https://ex.com | Suit les redirections, puis enregistre la page finale |
Je laisse -L activé presque par réflexe sur tout ce que je n'ai pas testé, parce que les rebonds de http:// vers https:// sont partout aujourd'hui et que ça, à soi seul, c'est déjà une redirection. Le seul moment où tu pourrais ne pas le vouloir, c'est quand tu débugues justement la redirection, et que tu préfères voir le 301 plutôt que de passer par-dessus.
Inspecter les en-têtes sans le corps
Parfois la page tu t'en moques complètement. Tu veux le code de statut, le type de contenu, peut-être un en-tête de cache ou la cible d'une redirection. -I te donne exactement ça : les en-têtes de réponse et rien d'autre. C'est la façon la plus rapide de demander à un serveur "tu es vivant et tu vas m'envoyer quoi".
| Commande | Ce qu'elle fait |
|---|---|
curl -I https://ex.com | Affiche les en-têtes de réponse seuls, sans corps |
curl -I -L https://ex.com | Montre les en-têtes à chaque saut d'une chaîne de redirections |
curl -s -I https://ex.com | En-têtes seuls, avec le bruit de progression coupé |
Un point à savoir : -I envoie une requête HEAD, pas un GET. La plupart des serveurs gèrent ça très bien et renvoient les mêmes en-têtes qu'un GET. Mais certaines applis, surtout les maison, traitent HEAD bizarrement, voire ne l'implémentent pas du tout, et tu récoltes un statut étrange ou une réponse vide qui fait croire que le serveur est mort alors qu'il ne l'est pas. Quand une réponse HEAD sent le roussi, recommence avec curl -sS -D - -o /dev/null https://ex.com, qui fait un vrai GET mais jette le corps et n'affiche que les en-têtes.
Envoyer des données et du JSON à une API
Tester un point d'API à la main, c'est l'autre terrain de jeu de curl. -d envoie un corps de requête, et dès que tu ajoutes un corps, curl bascule discrètement la méthode en POST à ta place, donc -X POST est souvent facultatif. Pour un formulaire HTML classique, tu passes juste les paires clé-valeur. Pour une API JSON tu envoies la chaîne JSON et, surtout, tu dis au serveur que c'est du JSON via un en-tête content-type, sinon pas mal de backends refuseront de l'analyser.
| Commande | Ce qu'elle fait |
|---|---|
curl -X POST -d 'a=1&b=2' https://ex.com | POST de données de formulaire, les paires clé=valeur classiques |
curl -H "Content-Type: application/json" -d '{"id":7}' https://ex.com/api | POST d'un corps JSON avec le content-type pour qu'il soit analysé |
curl -X POST -d @payload.json -H "Content-Type: application/json" https://ex.com/api | Envoie un corps JSON depuis un fichier avec @ |
curl -F 'file=@report.pdf' https://ex.com/upload | Envoi multipart, comme se comporte un vrai formulaire d'upload |
L'astuce du @, c'est celle que j'oublie et que je redécouvre tous les quelques mois. -d @payload.json lit le corps directement depuis un fichier, ce qui vaut mieux que de tasser un énorme bloc JSON sur une seule ligne et de te bagarrer avec ton shell pour les guillemets. Et -F c'est un monde à part : il fait un vrai envoi multipart, pose les frontières, tout le bazar, donc dégaine -F file=@chemin quand tu imites le formulaire d'upload d'un navigateur, pas -d.
Authentification, en-têtes, et voir ce qui se passe
Le reste du kit utile, c'est s'identifier et regarder ce qui circule sur le fil. Des en-têtes personnalisés pour les jetons. L'auth basique pour les vieux trucs. Et l'option verbeuse pour quand une requête échoue et que le message d'erreur ne t'apprend rien.
| Commande | Ce qu'elle fait |
|---|---|
curl -H "Authorization: Bearer T" https://ex.com | Envoie un en-tête personnalisé, ici un jeton bearer |
curl -u user:pass https://ex.com | Auth basique, curl construit l'en-tête Authorization pour toi |
curl -v https://ex.com | Verbeux : toute la requête et la réponse, en-têtes et poignée de main TLS |
curl -k https://self-signed.ex.com | Ignore les vérifs de certificat sur un hôte auto-signé (prudence) |
curl --resolve ex.com:443:127.0.0.1 https://ex.com | Truque le DNS, pointe un nom d'hôte vers une IP sans toucher au fichier hosts |
Ce --resolve, c'est une petite perle discrète pour les tests. Il épingle un nom d'hôte sur une IP pour cette unique requête, donc tu peux viser un nouveau serveur avant que le DNS ait basculé, ou tester une machine de préprod qui répond sur le nom de prod, le tout sans toucher à /etc/hosts. Le certificat TLS doit toujours correspondre au vrai nom d'hôte, ce qui est exactement ce que tu veux quand tu vérifies une mise en prod.

{kind=link}
Mon avis : tape -sS, presque jamais -s tout seul. Quand tu rediriges curl dans un pipe ou que tu le lances dans un script, tu voudras -s pour tuer la barre de progression et le bruit. Le piège, c'est que le -s tout seul fait aussi taire les messages d'erreur, donc une requête qui échoue franchement se contente de se taire et ton script continue comme si de rien n'était. La parade c'est -sS : le s minuscule coupe la barre de progression, le S majuscule fait revenir les erreurs. Du coup curl -sS https://api.ex.com/x | jq reste propre quand tout va bien mais te prévient vraiment quand le serveur renvoie un 500 ou que la connexion lâche. Je dégaine -sS plutôt que le -s nu quasiment à chaque fois maintenant. C'est peut-être trop prudent pour un coup unique que tu regardes en direct, mais dans tout ce qui est automatisé ça m'a évité de courir après des pannes fantômes plus d'une fois.
Et après
Voilà le vrai kit de travail. Télécharger avec -O ou -o, suivre les redirections avec -L, jeter un oeil aux en-têtes avec -I, faire un POST avec -d et un content-type, des en-têtes personnalisés avec -H, l'auth, le verbeux pour fouiller, et les quelques arêtes vives comme --resolve et la reprise. Franchement ça couvre presque tout ce que je fais avec curl dans une semaine normale, et le truc vraiment rare je le cherche comme tout le monde.
Puisque tu tripotes déjà du HTTP, deux ou trois de ces outils s'associent bien à curl. Quand -I te crache un mur d'en-têtes, un vérificateur d'en-têtes HTTP te les présente lisiblement. Perdu devant le numéro renvoyé ? Une explication des codes de statut HTTP te dit ce que veut dire un 429 ou un 502. Pour vérifier qu'un site répond depuis l'extérieur, il y a le vérificateur de statut de site web. Et quand tu retournes au shell pour traquer une connexion, les commandes réseau Linux avec ip et ss ont ces recettes regroupées de la même façon.
Sources
Questions fréquentes
Comment télécharger un fichier avec curl ?
Utilise curl -O https://ex.com/file.zip avec un O majuscule pour l'enregistrer sous le nom distant. Mets un -o out.zip minuscule si tu veux choisir le nom toi-même. Ajoute -L pour qu'il suive les redirections, parce que la plupart des liens de téléchargement rebondissent d'abord vers un CDN ou un miroir, et le -O sans -L enregistrera la page de redirection au lieu du vrai fichier.
Pourquoi curl ne suit-il pas la redirection ?
Parce que curl ne suit pas les redirections par défaut. Quand un serveur répond par un 301 ou un 302, curl affiche cette réponse et s'arrête, donc on a l'impression de n'avoir rien récupéré d'utile. Ajoute -L et curl suit la chaîne jusqu'à la vraie destination. C'est la surprise curl la plus fréquente, et -L est la parade que tu dégaineras sans arrêt.
Comment faire un POST de JSON avec curl ?
Envoie la chaîne JSON avec -d et règle le content-type, comme curl -H "Content-Type: application/json" -d '{"id":7}' https://ex.com/api. Ajouter un corps bascule la méthode en POST automatiquement, donc -X POST est souvent facultatif. Sans l'en-tête content-type beaucoup de backends refusent d'analyser le corps. Pour une grosse charge utile utilise -d @fichier.json pour le lire directement depuis un fichier.
Quelle est la différence entre curl -s et -sS ?
Le -s minuscule est silencieux, ce qui masque la barre de progression mais aussi les messages d'erreur, donc une requête échouée se tait. -sS reste silencieux en cas de succès tout en laissant passer les erreurs, parce que le S majuscule les réactive. Dans un script ou un pipe, comme curl -sS https://api.ex.com/x vers jq, préfère -sS pour qu'une erreur serveur ou une connexion coupée apparaisse vraiment au lieu d'échouer en silence.
Comment envoyer seulement une requête HEAD avec curl ?
Lance curl -I https://ex.com pour récupérer les en-têtes de réponse seuls, sans corps. Ça envoie une requête HEAD plutôt qu'un GET. La plupart des serveurs gèrent ça très bien, mais certaines applis traitent HEAD bizarrement ou pas du tout, renvoyant un statut étrange ou une réponse vide. Dans ce cas, utilise curl -sS -D - -o /dev/null https://ex.com, qui fait un vrai GET mais jette le corps et n'affiche que les en-têtes.