Un PSOD VMware ESXi vient de lâcher toutes les VM du host et balance un mur de texte violet sur la console. C'est le Purple Screen of Death, la version ESXi du blue screen de Windows : le VMkernel est tombé sur un truc dont il ne pouvait pas se remettre et s'est figé volontairement, plutôt que de gribouiller n'importe quoi sur les données de tes VM. On dirait la fin du monde. En général, ça ne l'est pas. Cet écran, c'est en gros un aveu, et une fois que tu sais quelles lignes lire, il te pointe direct vers le coupable. Voilà l'ordre dans lequel je traite un PSOD. Lire l'écran, le ramener à l'un des cinq suspects habituels, récupérer le core dump tant qu'il est encore là, remonter le host, puis m'assurer que la même chose ne m'attend pas la semaine d'après.
The short answer
Un PSOD, c'est le VMkernel qui s'arrête volontairement pour protéger les données
de tes VM. Lis cinq endroits sur l'écran (build, #PF Exception 14 ou LINT1/NMI,
la première frame du backtrace, le statut du core dump, la cible de dump), et
l'exception plus le nom de la première frame te donnent la cause à eux deux.
Photographie l'écran, récupère le core dump, puis fais un power-cycle du host et
va chercher le driver, le firmware ou le heap responsable.

{kind=link}
Un host vient de lâcher toutes les VM qu'il faisait tourner et balance un mur de texte violet sur la console. Bienvenue dans le Purple Screen of Death (PSOD), la version ESXi du blue screen de Windows. Le VMkernel est tombé sur un truc dont il ne pouvait pas se remettre, et il s'est figé volontairement. L'alternative ? Le laisser gribouiller n'importe quoi sur les données de tes VM, et ça, c'est pire. On dirait la fin du monde. En général, ça ne l'est pas. Cet écran, c'est en gros un aveu, et une fois que tu sais quelles lignes lire, il te pointe direct vers le coupable. Voilà l'ordre dans lequel je traite un PSOD. Lire l'écran. Le ramener à l'un des cinq suspects habituels environ, récupérer le core dump tant qu'il est encore là, remonter le host, puis m'assurer que la même chose ne m'attend pas pour me mordre la semaine d'après.
Ce qu'est vraiment un PSOD
Sous le capot, ESXi est un petit noyau dédié, le VMkernel, posé directement sur le métal. Quand il bute sur un truc à partir duquel il ne peut pas continuer à tourner sans danger (un accès mémoire foireux, ou une non-maskable interrupt remontée par le hardware, ou une vérification interne de cohérence qui ne tombe juste pas juste), il n'essaie pas de boiter. Il s'arrête net et peint cet écran de diagnostic violet. Continuer, ce serait parier avec les données de tes VM, ce qui est pire qu'une interruption de service, donc il ne le fait pas. Toutes les VM de la machine se figent à cet instant. Traite le PSOD comme un symptôme, jamais comme la maladie. La plupart du temps, le vrai coupable est un driver capricieux, ou du hardware en fin de vie. Un vrai bug d'ESXi ? Celui-là est rare, et franchement je parierais contre avant de parier dessus, même si j'avoue avoir été surpris une ou deux fois.
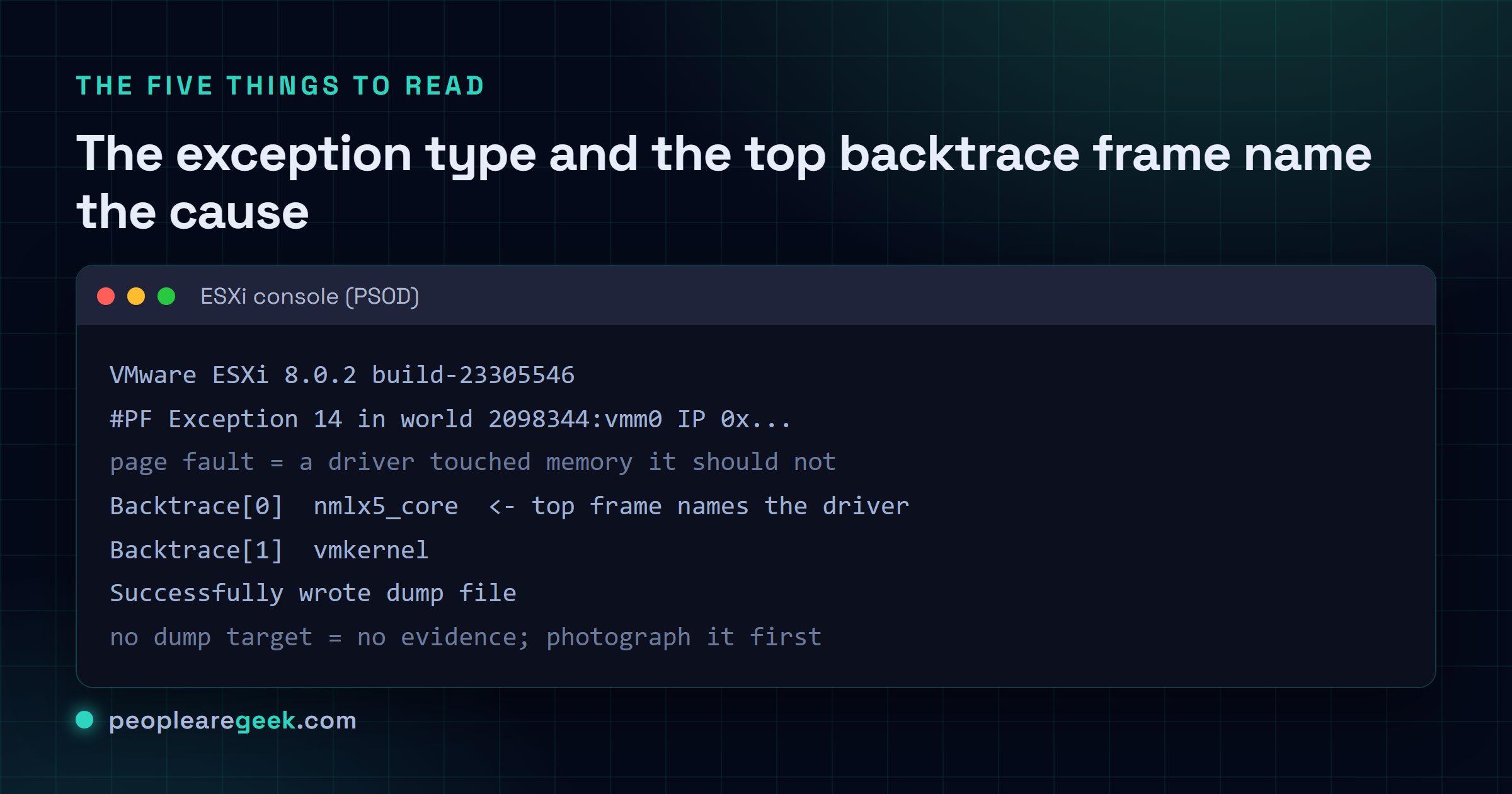
Les cinq choses à lire sur l'écran
Premier réflexe, avant de poser un doigt sur le clavier : photographie l'écran entier. Ensuite, passe en revue ces cinq endroits. C'est là que se planque la réponse.
- Le build ESXi tout en haut. Tu en auras besoin plus tard pour vérifier le driver fautif dans le VMware Compatibility Guide pour ce build précis. Le « à peu près » ne compte pas ici, et je l'ai appris à la dure.
- Le type d'exception. Un
#PF Exception 14est un page fault, ce qui veut dire qu'un driver est allé toucher de la mémoire qui ne le regardait pas. Tu vois plutôtLINT1 motherboard interruptouNMI? Ça, c'est remonté du hardware. Un message VMFS ou heap, c'est le stockage qui te fait signe. - Le haut du backtrace. Lis de haut en bas. Le premier module nommé est presque toujours ton bonhomme : un driver de NIC, ou un driver de storage HBA, peut-être un plugin de multipathing. Tout ce qui est en dessous, c'est surtout le noyau qui s'écroule. C'est cette première ligne qui m'intéresse.
- Le statut du core dump. « Successfully wrote dump file », c'est la ligne que tu espères, parce que là tu as quelque chose à creuser. « No place on disk to dump data » veut dire que rien n'était prévu pour le rattraper. Tu viens de perdre ta preuve.
- Et même : est-ce qu'une cible de dump existe. Si non, règle ça avant tout le reste, pour que le prochain PSOD te laisse vraiment de quoi travailler.

{kind=link}
Les causes derrière la quasi-totalité des PSOD
| Signature à l'écran | Cause la plus probable |
|---|---|
#PF Exception 14 + un nom de driver | Driver défaillant ou non aligné (NIC, HBA, RAID), mets à jour ou reviens à la version HCL du driver |
LINT1 / NMI | Hardware : mémoire défectueuse, CPU ou carte PCIe en train de lâcher, va voir les logs hardware du serveur |
| Épuisement VMFS / heap | Le heap du stockage est à sec, augmente le réglage du heap ou mets ESXi à niveau ; rééquilibre les gros VMDK |
PCPU N locked up | Un CPU coincé dans un spinlock driver/firmware, en général le firmware ; mets à jour le BIOS et le driver mis en cause |
| Répété après un changement récent | Le driver, le firmware ou le VIB que tu viens d'installer, reviens en arrière |
Si je devais parier sur ce qui se cache vraiment derrière un PSOD sur le terrain, je mise sur un driver réseau ou stockage qui ne colle pas avec le build ESXi. Il adore débarquer juste après un upgrade, là où l'inbox driver a glissé en douce sous tes pieds sans que personne le remarque. Deuxième place ? Le hardware, et en général ça veut dire la mémoire. Donc lis la ligne d'exception et trouve dans quelle famille tu te trouves. À ce stade, l'essentiel du diagnostic est déjà derrière toi. Ce qui reste, c'est surtout confirmer l'intuition.
Capturer le core dump avant de rebooter
Le core dump, c'est l'or ici. C'est ce qui te permet, à toi ou au support VMware une fois le ticket ouvert, d'épingler l'instruction exacte qui a explosé. Pas un vague « un truc dans le driver de stockage », l'instruction réelle. Donc avant tout, assure-toi qu'il y a un endroit où le host peut en écrire un :
esxcli system coredump partition list
esxcli system coredump partition get
# si aucune n'est définie, configure la partition de diagnostic locale :
esxcli system coredump partition set --enable true --smart
# ou envoie les dumps vers un collector réseau :
esxcli system coredump network set --interface-name vmk0 \
--server-ipv4 10.0.0.50 --server-port 6500 --enable trueTu as un dump ? Parfait. Une fois le host revenu, lance vm-support pour le regrouper avec les logs qui vont avec. C'est cette archive-là que tu donnes au support. Ça t'évite le « pouvez-vous aussi nous envoyer le vmkernel log », celui qui arrive toujours trois mails plus loin.
Sérieusement, ne reboote pas un host en PSOD avant d'avoir photographié l'écran. À la seconde où il redémarre, le backtrace à l'écran est perdu pour de bon. La seule chose qui survit au reboot, c'est le core dump, et encore, à condition qu'un dump ait bien été écrit au départ.
Récupérer le host
Le host est planté. Pas de sauvegarde en douceur ici. La récupération, c'est un redémarrage propre, puis le vrai boulot de comprendre pourquoi. Dans cet ordre :
- Redémarre le host. Fais un power-cycle via le contrôleur out-of-band (iLO, iDRAC, peu importe le nom que ton constructeur lui colle), ou va le faire à la main s'il le faut. Les VM remontent dessus. Ou HA les redémarre ailleurs, à condition que tu l'aies configuré à l'avance.
- Vérifie qu'il est revenu proprement. Lance
esxcli system version get, puis lis/var/log/vmkernel.logpour voir ce qui s'est passé dans les secondes juste avant le crash. C'est en général là que la miette de pain t'attend. - Va chercher la cause. Mets à jour ou reviens en arrière sur le driver que le backtrace a nommé (
esxcli software vib list | grep <driver>), pousse un firmware frais si c'était une panne hardware, ou ajuste le réglage si tu as mis un heap à sec. Tu sais déjà lequel grâce à la ligne d'exception. - S'il recrashe tout de suite, arrête de te battre en live. Bascule le host en maintenance mode et sors les VM, pour qu'une boucle de crash n'entraîne pas tes workloads avec elle toutes les cinq minutes.
Empêcher que ça recommence
- Vis sur la HCL. Ne fais tourner que les versions de driver et de firmware que VMware liste réellement face à ton build ESXi exact. Pas la plus récente, celle qui est listée. Si je rabâche ça, c'est que la plupart des PSOD que j'ai chassés remontent à quelqu'un qui s'en était écarté.
- Ne fais jamais tourner un host sans cible de dump. Un PSOD qui n'a rien écrit, c'est une interruption de service que tu as payée sans rien en apprendre, et celle-là, elle pique. Configure une partition ou un network dump collector sur chaque host, sans exception.
- Déplace firmware et drivers en couple. Utilise l'ESXi custom image ou l'addon de ton constructeur de serveur pour que les deux restent au pas. Mettre l'un à jour et oublier l'autre, c'est en gros la recette pour fabriquer ton prochain écran violet.
- Teste la mémoire de tout host qui est tombé sur un NMI hardware avant de lui refaire confiance en production. Un reboot qui « répare » le truc veut juste dire que la DIMM défectueuse est toujours là, à t'attendre.
- Garde ESXi raisonnablement à jour. Les builds plus récents relèvent discrètement les limites de heap et corrigent les pires bugs d'interaction driver, du coup une bonne partie des problèmes de cette page arrête tout simplement d'apparaître.
Sources et pour aller plus loin
Questions fréquentes
Un PSOD est-il toujours un bug VMware ?
Presque jamais, et je prends le pari avec plaisir. La grande majorité se ramène à un driver tiers qui ne correspond pas au build ESXi, ou à du hardware en fin de vie (en général la mémoire). ESXi ne s'arrête que pour protéger tes données, et il dépose le vrai coupable juste là, sur l'écran, pour toi. Donc commence par le traiter comme un problème de driver ou de hardware, pas comme un problème VMware. Tu auras raison bien plus souvent que tort.
Que veut dire #PF Exception 14 sur un PSOD ?
C'est un page fault. Un module noyau est allé chercher de la mémoire qu'il n'avait pas le droit de toucher. C'est l'empreinte classique d'un driver buggé ou mal aligné, et honnêtement c'est celui que je croise le plus. Quel que soit le module en haut du backtrace, c'est ta cible. Mets-le à jour, ou reviens à la version que le VMware Compatibility Guide dit appartenir à ton build.
Comment trouver la cause s'il n'y a pas de core dump ?
Pas de dump veut dire que tu travailles avec moins, mais pas avec rien. Tu t'appuies sur la photo que tu as prise (type d'exception, plus cette première frame du backtrace) et sur /var/log/vmkernel.log juste avant que ça tombe. Souvent ça suffit à nommer la famille. Ensuite, et je veux bien dire aujourd'hui plutôt que « quand j'aurai le temps », configure une partition de core dump ou un network collector. La prochaine fois, tu auras le tableau complet au lieu d'un jeu de devinettes.
Puis-je récupérer les VM qui tournaient sur le host ?
Elles sont tombées brutalement quand le host s'est figé. Imagine qu'on arrache le câble d'alimentation, pas un arrêt propre. Une fois le host revenu, elles redémarrent dessus, ou vSphere HA les remonte sur un autre host si tu as HA en route, et elles reviennent à leur dernier état écrit sur disque. La seule chose que tu perds vraiment, c'est l'I/O en vol qui n'a jamais atteint le disque. Donc oui, HA plus du stockage en qui tu as confiance gagne discrètement son salaire un mauvais jour.
Quelle est la différence entre un PSOD et un host affiché en Not Responding ?
Le jour et la nuit, même si les deux donnent l'impression que « le host est mort ». Un PSOD est un arrêt noyau franc. Écran violet, console figée, le VMkernel est fini. « Not responding » dans vCenter veut généralement dire que le host est vivant et en pleine forme, mais que son agent de management a perdu le fil, ce qui est un problème bien plus doux que tu peux souvent régler sans rebooter quoi que ce soit. L'indice, c'est la console. Ouvre la console physique ou distante et tu sauras en deux secondes lequel des deux tu as sous les yeux.