AI Hallucination Risk Estimator
Paste any LLM response and see where it probably made things up, with a 0 to 100 risk score and a checklist of what to verify.
This AI hallucination risk estimator reads any LLM response the way a tired, suspicious editor would and points you at the parts that probably got invented. Paste the answer, plus the prompt if you kept it, and twelve heuristics hunt the usual tells: citations with no link, weirdly precise dates and percentages, fake-smelling URLs, quotes pinned on real people, dollar figures, confident absolutes with zero hedging. Back comes a 0 to 100 risk score, a breakdown of what tripped, the exact words that set off each flag, and a short checklist before you ship. Hand it the prompt too and grounded facts earn a discount. It will not fact-check anything; treat the number as a where-to-look signal, not ground truth. Everything runs in your browser, so confidential drafts never leave the page.
100% in your browser. Nothing you type ever leaves this page.

{kind=link}
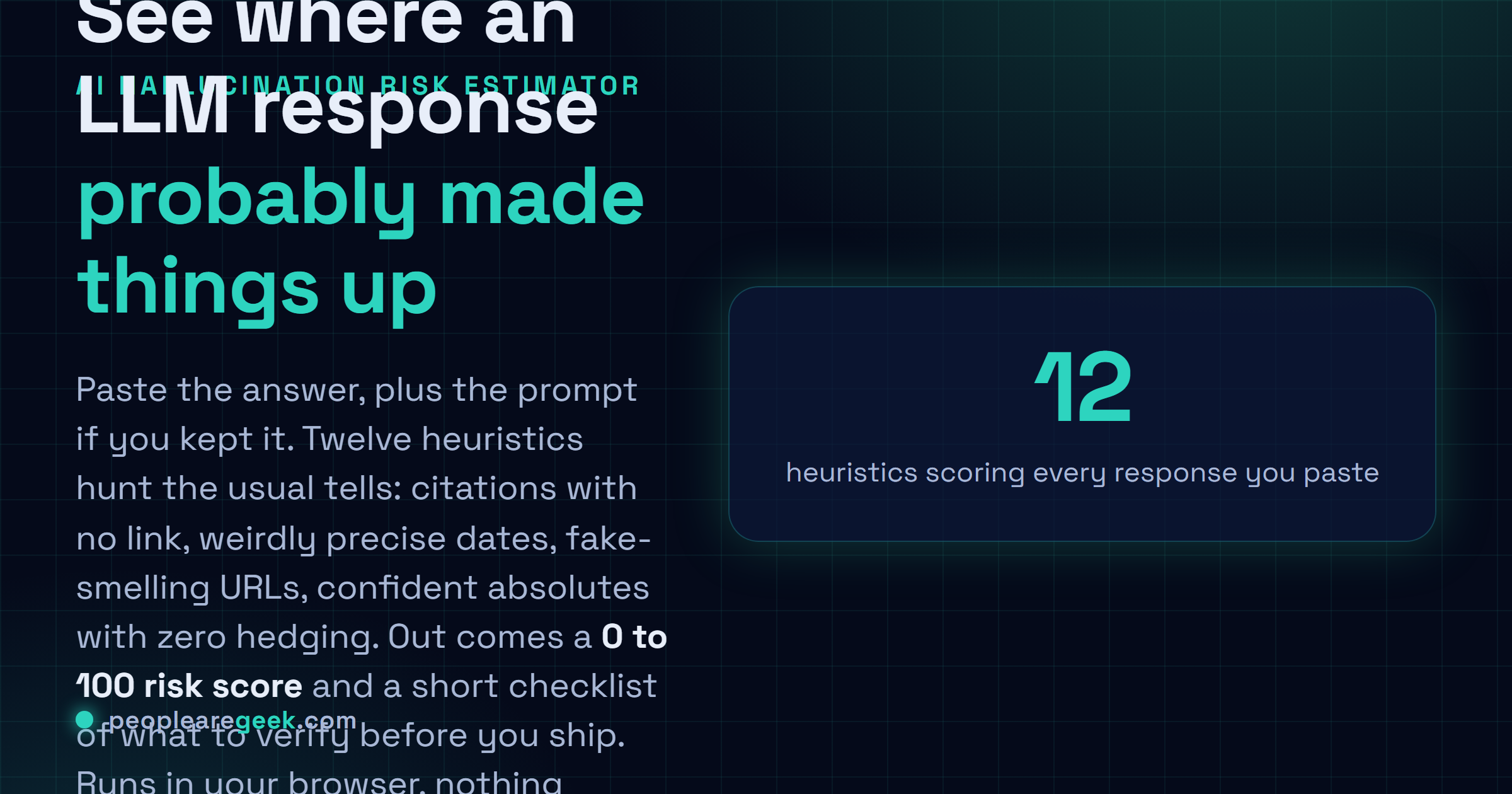
LLM output hallucination risk estimator
You know that half-second before you hit publish on something a model wrote? The little voice going "wait. did it just make that up?" I built this for that exact moment. Paste the response in, plus the prompt if you kept it, and it reads the text the way a tired, suspicious editor would. Twelve heuristics hunt the usual suspects. Citations with no link. Dates that are weirdly precise. Confident absolutes with not a shred of hedging, quotes pinned on real people, dollar figures, fake-smelling URLs. Out comes a 0-100 risk score, a breakdown of what tripped, the exact words that set off each flag, and a short checklist before you ship. It won't fact-check anything. Honestly, it just points and says: look there first.
No data leaves your browser. The estimator runs locally and is heuristic; treat the score as a triage signal, not as ground truth.
Why a hallucination risk estimator matters in 2026
They still make things up. Doesn't matter how good the model is. GPT-5.5, Claude Opus 4.7, Gemini 3 Pro, every one of them will hand you a confidently wrong answer the second you ask a sharp factual question with nothing to ground it. Or when you need a date pulled from memory. Or when you drift near the training cut-off. Here's the part I find genuinely useful, though: the lie is almost never random. It has a shape. The model conjures up a URL that looks flawless and 404s, puts words in a mouth that never said them, cites a study nobody wrote, invents a percentage that rounds a touch too cleanly. And it gets loudest right when it knows least. Learn those tells once, catch them before a human ever sees the thing, and you dodge most of the cringe.
So, mechanically: it runs twelve quick heuristics over whatever you paste. Each one chases a known tell and adds a weighted nudge to the pile. The number that comes back isn't the odds your answer is wrong. It's a where-to-look signal, basically, pointing at the sentences that earned a second pair of eyes. Under 25? You're probably fine after a glance. 25 to 55, go check a couple of claims first. Over 55, don't ship until a human has actually verified the facts. I might be too cautious there, but I'd rather over-flag than eat a correction.
How the estimator scores a response
- Tokenise the response. It gets chopped into sentences and rough phrases so the patterns have something to bite on.
- Run the heuristics in parallel: precise dates, percentages, currency figures, named entities, "according to" attributions with no URL, fabricated-looking URLs (arxiv.org links with IDs that don't exist, say), confident absolutes like always and never, invented paper titles, lab studies with no citation, missing hedges, and whether a claim is grounded in your prompt or pulled from thin air. Each check is small and dumb and fast. Stacked together, though, they cover a surprising amount of ground.
- Compute a weighted sum. Every heuristic carries a per-occurrence weight, since not all tells are equal. An unsupported percentage costs you 6 risk points. A fake-looking URL, a heftier 12. Add it all up, cap it at 100.
- Apply the prompt-grounding bonus: hand it the original prompt, and if those same facts show up there, the score drops. The model's echoing what you fed it instead of inventing, and that deserves credit.
- Render the verdict: green, amber or red bands, the exact spans that tripped, plus fixes sorted by how much they'd actually move the needle.
Common use cases for the estimator
- Pre-publish review of AI-assisted content. Honestly, this is what I reach for it most. A blog post, marketing copy, some internal doc the model drafted: give it a quick pass before a human stakes their name on it.
- RAG pipeline QA. Retrieval won't save you. The model still wanders off the source whenever it feels like it. Push a sample of your generations through and the drift shows up, which is what tells you whether to go fix the retriever or the system prompt.
- Customer-facing chatbot guardrail. About to fire a long answer at a user? Score it first. Comes back over 55, you throw up a confidence warning or quietly hand it to a human.
- Teaching people what to watch for. Sit a new teammate down with a handful of risky answers and the flags do the explaining for you. Pretty soon they're catching the patterns without it.
- Compliance and risk. In a regulated shop, "we ran every AI output through a triage step" is just a nice line to have sitting in the audit trail.
- Prompt iteration. Put two versions of a prompt up against the same question, keep whichever scores lower. Most of the time the winner's the one with hedging instructions or grounding baked in.
Limitations and honesty notes
Straight talk about what this is and isn't. It's a pattern-matcher. It checks nothing against the real world. No web searches, no vector database, no oracle whispering the truth. It reads the surface of the text and that's it. So a calm, beautifully hedged answer that's dead wrong will sail through on a low score, while a perfectly correct one stuffed with dates lights up amber. The number tells a human where to look. It does not tell you what's true. And two patterns slip past it every single time. A fake citation that looks legit, where the journal and the year just happen to fit. And a confident claim about some niche corner where the model has zero data and zero hedge. Those need your eyes no matter what the number says.
None of this leaves your machine. The prompt, the response, every scoring step in between: all of it runs in your browser and never touches the PeopleAreGeek server. So paste in confidential drafts, customer transcripts, whatever's under NDA. Go for it. And if you want to see exactly how the sausage gets made, the patterns and weights are sitting right there in the Heuristics breakdown tab. The rest is in the page source.
Frequently asked questions
How accurate is the estimator?
Useful, not gospel. It's a heuristic, not a fact-checker. On the test set we built (roughly 400 LLM responses, half right and half wrong) the high scores track real hallucinations at about 0.7 correlation. That's a solid triage signal. It is not your excuse to skip a human on anything that actually matters.
Why does my hedged answer still score amber?
Hedging drags the score down. It does not wipe it clean. Drop in precise dates, percentages, a pile of named entities, and those still fire their own heuristics, hedge or no hedge. Amber is not a fail. It is the tool muttering "probably fine, but go double-check these couple of things first".
Can I use this on responses in other languages?
You can, with one caveat: the heuristics are tuned for English and French. The language-agnostic stuff (dates, percentages, URLs) works fine whatever you paste. But the hedge-word and citation patterns lean hard on specific phrasing, so in other languages they miss a chunk, and the score can read a little lower than the real risk. Worth knowing before you trust it on, say, German or Japanese.
What is the difference between an unsupported claim and a hedged claim?
An unsupported claim states it flat out, like saying France has 67.4 million inhabitants. A hedged claim waves its own uncertainty at you, like saying France has approximately 68 million inhabitants as of the most recent estimate. Basically the same number. But the second one is quietly nudging you to go check, and that bit of honesty is exactly what the estimator rewards.
Should I run the estimator before or after my RAG retrieval?
After. Every time. The retrieved chunks are just part of the prompt, and what you actually want to grade is the final answer the model built on top of them. So generate first, then run the estimator on the output. One bonus move: paste the retrieved context into the prompt field too, and you'll pick up the grounding discount on anything the model faithfully echoed back.
Is my input stored?
Nope. The whole thing runs in your browser. The prompt and response you paste get chewed through by JavaScript right here on the page, and not one HTTP request leaves while it analyses. Hit refresh and your inputs are gone for good. Nothing to store, since nothing ever left.